If you’ve read this blog before, you are likely to know what nanoparticles are: bits of matter on the 1-100 nm scale that have unique properties different from bigger sizes of the same material. But you might not know what we mean when we say “proteomics,” which sounds to me sort of like “proteins” + “Olympics”

Proteomics is actually a combination of the words “protein” and “genomics.” You might remember that each person’s genome is the sequence of all their genes from the start of the first chromosome to the end of the last chromosome. And, you might remember that genes are made of DNA, deoxyribonucleic acid. DNA is a polymer (a long molecule) – one strand of it consists of a sugar-phosphate backbone (deoxyribose is the sugar) that has a “base” attached to each sugar. There are 4 bases: (adenine (A), guanine (G), cytosine (C), thymine (T)). Thus, the genome can be described as the order of the all the bases across all the chromosomes in the person’s DNA. “Genomics” is the study of the genome.
Just like DNA is a polymer, proteins are also polymers. The building blocks of proteins are amino acids, connected to each other by what we call amide or peptide bonds. There are about 20 naturally-occuring amino acids. So, by analogy with the genome, we say that a list of all the proteins in an organism is its proteome. (Technically the proteome is coded by the genome, since DNA determines which proteins are made by each cell!)
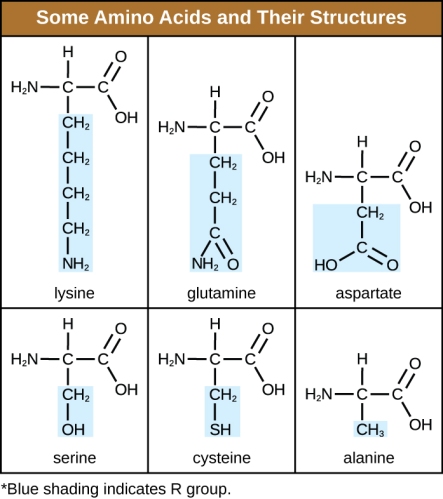
Proteins are the workhorses of biology: for example, the proteins myosin and actin make up muscle, the protein collagen is part of our connective tissue, hemoglobin is the protein that transports oxygen in our blood and makes it red, and so forth. Insulin is a small protein that functions as a hormone, regulating glucose levels in the blood. But even though we know a lot about how proteins work, figuring out the proteome of an organism is a lot harder than figuring out its genome. This is because proteins are continuously being produced in the body, then they are modified chemically, and in some cases they degrade over time. So although the genome has the DNA codes for all the proteins, it does not tell you how much of them are made and when. On top of that, proteins vary a lot in size: in solution, some are in the size range of nanoparticles (~10-100 nm) and some are far larger (1000 nm, or one thousandth of a millimeter).
So what do proteins have to do with sustainable nanotechnology? In the CSN we have done a lot of theoretical and experimental research about how individual proteins interact with a nanoparticle surface, at a very granular level. This is because we want to be able to understand a couple of things: first, how a nanoparticle might interact with a protein that is embedded in the membrane of a cell; and second, how a nanoparticle might interact with a protein that is floating around in liquid in or near an organism. If we understand these two things, we might be able to predict how a nanoparticle might impact live cells: Would it get inside? Stick to the outside? Dissolve and release extra ions to the cell? Clump up and block channels in the cell membrane?
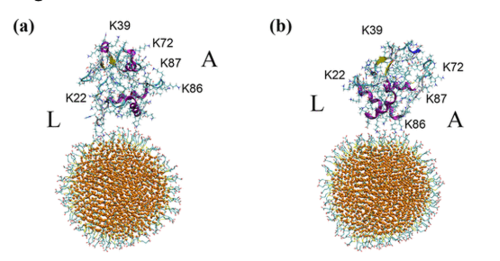
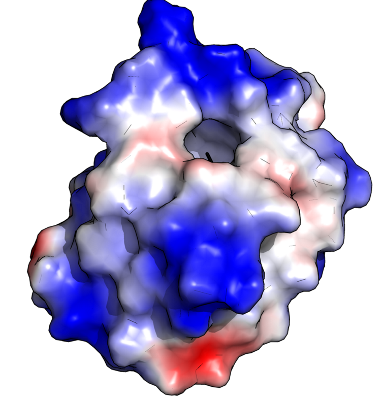
When we put a nanoparticle in solution (for example, dissolving it in water), and expose it to the innards of a cell, we would expect that molecules in the cell might stick to the nanoparticles, depending on the nature of the nanoparticle surface. For instance, proteins that have an overall positive charge might stick more to nanoparticles that are negatively charged (similar to how magnets of opposite poles attract each other). But it’s probably even more complicated than that, since most proteins have patches of positive and negative charge from their constituent amino acids that add up to the total net charge of the protein.
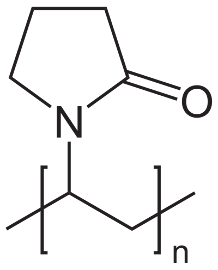
In the CSN we recently did a pretty big experiment to analyze all the proteins in a living cell (at least all above the detection limit of our technique) that were bound to some cool nanoparticles we made. The nanoparticles had a magnetic iron oxide core and a thin gold shell, overall about 200 nm in diameter. We coated the nanoparticles with PVP, a polymer that provides stability in water and has no net charge.
For the cells in the experiment, we got some trout gill cells (trout is a freshwater fish species used for research a lot), the idea being that in the real world fish might take up nanoparticles through their gills. We broke open the cells, and put all the cell innards (technically called cell lysate, which includes a bunch of proteins) in with our nanoparticles. Then, we centrifuged the nanoparticles down to a pellet, pulled off the proteins that were bound to them, and analyzed which ones had stuck. We then repeated this experiment, except that instead of centrifuging the nanoparticle-protein mixture, we went in with a magnet to gently retrieve the nanoparticles and their associated proteins. We expected that there would be a lot more proteins the gentle magnetic way, and that the roughly centrifuged proteins would be a subset of the magnetically-retrieved proteins.
However, we found this:
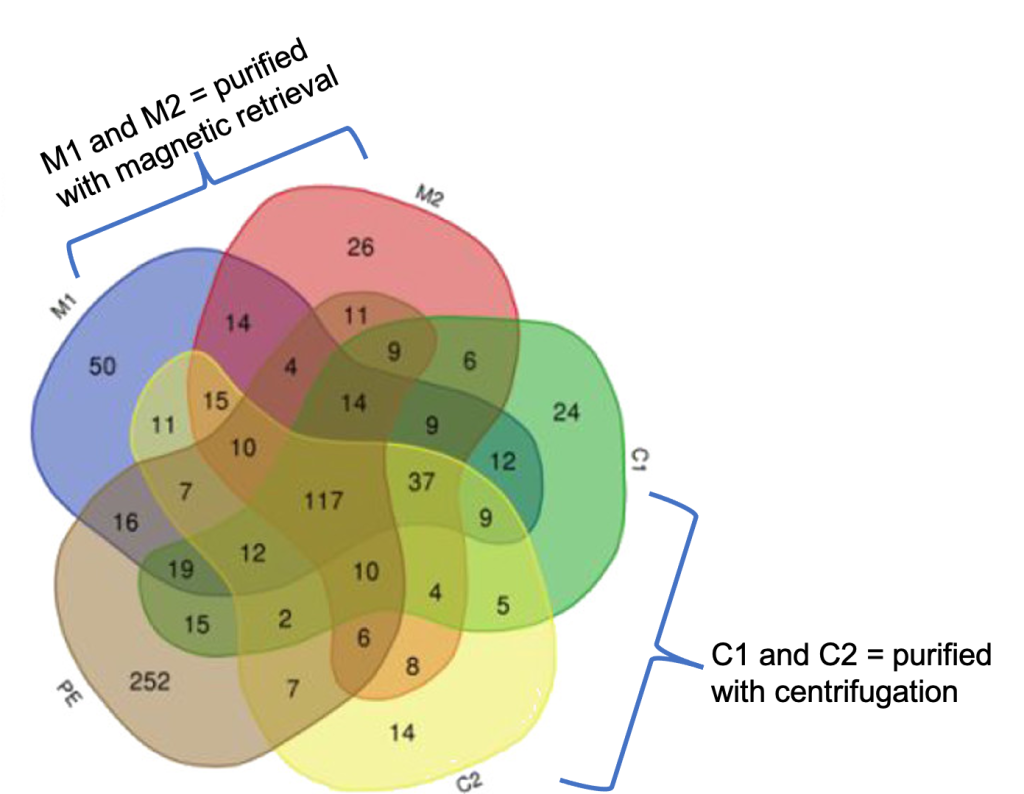
Each of the numbers you see in the figure tells us how many proteins were detected under various conditions (yes we have the full list). Each number tells how many proteins were detected in that condition, and the overlapping areas show the number of proteins that showed up in more than one category. PE is “protein extract,” which means what we were able to isolate and detect these proteins from the cells without any nanoparticles. C1 and C2 represent the conditions where we incubated the insides of the cell with the nanoparticles and purified the nanoparticles and their associated proteins by centrifugation once and twice, respectively; M1 and M2 represent the conditions where we incubated the insides of the cell with the nanoparticles and then purified the nanoparticles and their associated proteins by magnetic retrieval once and twice, respectively.
What does all this mean? It means that the history of the nanoparticle is encoded in its protein “fingerprint.” Look at M2: there are 26 unique proteins we found in that condition that show up nowhere else. Look at C2: there are 14 unique proteins that we found that show up nowhere else in the experiment (above the detection limit for the technique, of course). And what about those 117 proteins in the middle that show up in all samples? That list is interesting: many of them are involved in maintaining the redox potential of the cell, which is an important equilibrium state – when it gets out of balance, the cell can experience oxidative stress. So this collection of proteins might provide a clue for some mysterious observation that many labs report about oxidative stress in cells: even non-redox-active molecules or nanoparticles seem to generate oxidative stress responses in cells at a certain dose. How could this work? Well, maybe our data has an answer: if the molecules or nanoparticles are binding the proteins that maintain levels of oxidants and reductants in the cell, these proteins are less available, making the cell “out of tune” and thus generating an oxidative stress response via this indirect mechanism.
As chemists, we always get excited when we know how many molecules are in a certain place at a certain time. The experiments I just described don’t really tell us anything about time, but they do tell us about where a lot of different proteins end up when they’re placed close to certain nanoparticles. Adding the dimension of time would make things even more interesting: it would be super cool to know, for instance, the dynamic nature of an evolving “protein corona” around a nanoparticle as it gets into a cell, moves through the cell, ends up in some subcellular compartment, etc. We think that knowing the ever-changing surface coating of the nanoparticle as it goes about its business will provide the best predictor of the nanoparticle’s ultimate fate in a biological or environmental context.
REFERENCES
- Emily J. Tollefson, Caley R. Allen, Gene Chong, Xi Zhang, Nikita D. Rozanov, Anthony Bautista, Jennifer J. Cerda, Joel A. Pedersen, Catherine J. Murphy, Erin E. Carlson, and Rigoberto Hernandez. Preferential Binding of Cytochrome c to Anionic Ligand-Coated Gold Nanoparticles: A Complementary Computational and Experimental Approach ACS Nano, 2019, 13 (6), 6856-6866 DOI: 10.1021/acsnano.9b01622
- Khoi Nguyen L. Hoang, Korin E. Wheeler, and Catherine J. Murphy. Isolation Methods Influence the Protein Corona Composition on Gold-Coated Iron Oxide Nanoparticles. Analytical Chemistry, 2022, 94 (11), 4737-4746 DOI: 10.1021/acs.analchem.1c05243


{kind=link}